Google's DataBoost and Why You Should Know About It
In my new role on this team, we’re heavy users of Spanner. It’s used for operational workloads, and we also run pipelines that extract existing data so it can be consumed downstream. While looking at some metrics and the overall health of Spanner with the team, one thought kept coming back to me: if in PostgreSQL we use replicas for long-running extraction queries, doesn’t Spanner have something similar? It felt odd that it might not.
Here comes DataBoost.
What is DataBoost? Google describes it as a “serverless service that provides independent compute resources.” Nothing is truly serverless, but the promise was that we could query and export data with near-zero impact, which made it immediately relevant for this kind of workload. The promise was that we could keep Spanner’s consistency and fresh operational data while reducing impact on production workloads.
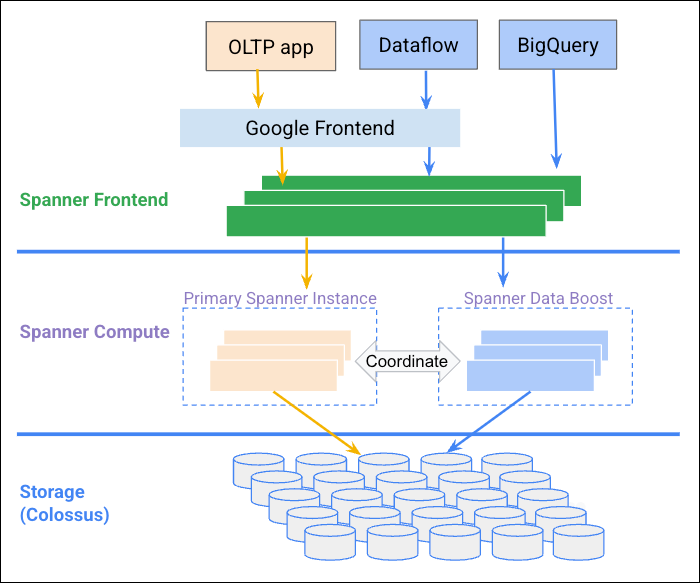
Read more: https://docs.cloud.google.com/spanner/docs/databoost/databoost-overview
So I got my hands dirty and opened up my IDE, but after reading the documentation, the change was basically a one-liner (o.O). It sounded too good to be true.
Still, we moved forward and deployed the change, and the results were clear. Pipeline runtimes were cut by 15%, and we still got the same fresh data Spanner has accustomed us to. Of course, this also had a strong impact on CPU by massively dropping our node count. It’s still strange how well this is working: for the heavy loads we run, it feels like that pressure just disappeared. The joys of serverless.
The lesson here? Old habits and patterns are still very relevant. It’s interesting how a simple concept I learned and implemented in many PostgreSQL instances became one of the most impactful things I’ve done in my professional life.